绿联NAS社区是一个属于绿联用户的社区,是讨论和交流绿联产品有关的社区,我们将尽量保持社区交流的宽松环境,但同时也希望您在社区中保持文明交流。对不文明和违反社区相关管理规定的行为,我们将采取必要的管理措施。 进入社区前,您需要明确阅读并知悉《绿联NAS社区用户协议》《绿联NAS社区隐私政策》《绿联NAS社区公约》《绿联NAS社区积分规则》《绿联NAS社区版块规范》《绿联NAS社区申诉专区规范》和其他绿联在您使用本社区时,向您公布的其他协议、规则、声明、指引、政策等。 点击“同意”即代表您同意上述规则,并同意我们收集并处理您的个人信息(包括敏感个人信息),并帮助您注册账号、提供信息服务。 请您注意,若您选择“不同意”,您将只能作为游客使用绿联NAS社区,可使用功能仅包括基本内容的浏览,您可以随时注册账号以获得更丰富的体验。
同意 不同意
IP:–河南 /全省通用
您需要 登录 才可以下载或查看,没有账号?立即注册
Hindsight 不是 Hermes 内存中的一层,而是整个“大脑”中的专业记忆中枢。
我是设计虱聊科技——坚持创作有深度、高质量的作品、致力于分享干货、抵制标题党和网络垃圾,是我的座右铭。让我们共同打造互联网内容创作和知识分享的一股清流!ヾ(◍°∇°◍)ノ゙
举报
本版积分规则 发表回复 回帖后跳转到最后一页
1
63
1769
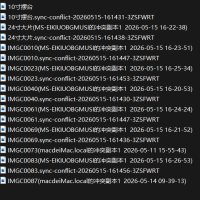 为了绿联的同步功能,花大价钱换了电脑,同438 人气#用户互助
为了绿联的同步功能,花大价钱换了电脑,同438 人气#用户互助 绿联NAS私有云绿联NAS私有云
绿联NAS私有云绿联NAS私有云 孙笑川258
孙笑川258 梦梦
梦梦




